Explorations on Adversarial Robustness in Vision
This blog contains some of my explorations on why vision models are sensitive to adversarial input-space perturbations. I test two hypotheses of the contributors of this type of non-robustness: image normalization and pooling operations.
I. Role of Image Normalization
Each real image read by computers contains integers from 0 to 255 per pixel per channel, so their datatype is ordinal rather than floats as we usually feed into neural networks. The former has a much smaller number of possible states and might be of different difficulty to be modeled by our current models. Therefore,
I study whether our treatment of image data as floats rather than its natural form as ordinals has complicated the visual learning problems.
To examine this hypothesis, I standardly train two randomly initialized ViT-tiny models, Baseline and Round, on CIFAR-10 and CIFAR-100.
-
Baseline is trained by a normal pipeline:
transform loaded image from [0, 255] to [0, 1] -> normalize -> resize -> feed to ViT -
Round is trained by a “rounded” pipeline:
transform loaded image from [0, 255] to [0, 1] -> resize -> round by torch.round(x*255)/255. -> feed to ViT
The rounding layer is turned off when we calculate adv samples. So Round differs from Baseline by- trained with no image normalization
- never see an invalid image input
Experiment: I standardly train Round and Baseline for 40 epochs with 3 seeds respectively, whose clean-adv accuracy tradeoff are as below. In Figure 1, one dot is one epoch’s test result, and each line connects the average result of 3 runs.
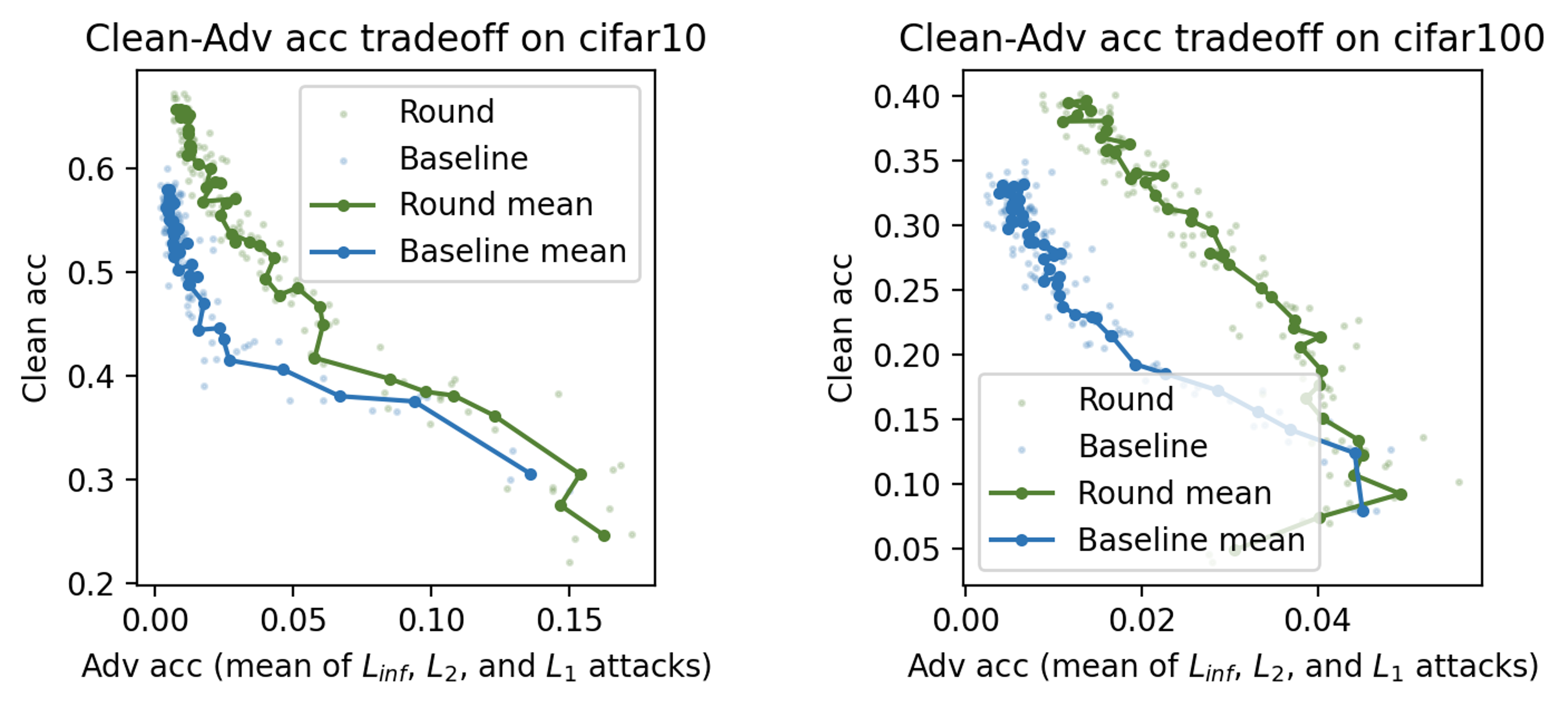
Takeaway: Round displays better clean-adv tradeoff than Baseline, though in the later stage of standard training, their adv acc all become 0. One implication of this is a project studying how data continuity interacts with the different model operations and the training dynamics. In my option, it is likely that the more discrete/quantized the data is, the more robust they are in front of adversarial attacks.
II. Role of Pooling Operations
Some pooling operations might be more sensitive to input change, which could contribute to non-robustness. In the following toy experiment, I compare whether maxpool and avgpool makes a difference on clean-robust accuracy tradeoff on cifar10.
I standardly trained two randomly-initialized ResNet18 models, Max and Avg, on cifar10. All the training configurations are the same except that the max pooling operations in ResNet18 is replaced with avg pooling in Avg.
Experiment: I standardly train Max and Avg for 10 epochs with the same hyperparameters, whose clean-adv accuracy tradeoff are as below where one dot represents one epoch’s test result.
Takeaway: Max displays better clean-adv tradeoff than Avg, though in the later stage of standard training, their adv acc all become 0. To see whether maxpool brings about better tradeoff consistently, one potential next step can be probing the layers’ feedback to varied inputs or conducting layer patching and retraining.