Low-Rank Fine-tuning Forgets More
Abstract
Low-rank fine-tuning (LoRA) of a pretrained language model on downstream tasks is a widely adopted efficient method, but its effects on catastrophic forgetting, i.e., resulting in degraded performance on old pre-trained knowledge, are unclear. In this work, we study Phi-1.5B and Llama-2-7B and observe that
1. LoRA forgets more: large ranks have better old-new knowledge performance tradeoffs.
2. This trend holds especially well when the new and old knowledge are of the same domain.
1. Motivation
Low-rank fine-tuning (LoRA) of a pretrained language model on downstream tasks is a widely adopted efficient method. LoRA freezes the pre-trained two-dimensional weights $W$ and learns two matrices \(A\) and \(B\) so that \(W+AB\) performs well on the new dataset. Researchers commonly set the rank to 8, and notably, applying this rank to all the Linear layers of the Phi-1.5 model saves over 10 times of memory during fine-tuning under the same batch size and sequence length.
However, does the memory-efficiency of LoRA come at a price? It is common and undesired that fine-tuning on new data results in degraded performance on old pre-trained knowledge, known as catastrophic forgetting. Therefore, in this work, we examine the question
Does low-rank fine-tuning forget more? Why or why not?
2. Experiment Setup
The problem of focus is fine-tuning large language models (LLMs), including Phi-1.5B and Llama-2-7B, on Q&A tasks. We measure the ROUGE score on the fine-tuned data and on data that represents old knowledge to examine the old-new knowledge performance tradeoff.
Specifically, we fine-tune a pre-trained LLM on the TOFU
Another metric is named “Truth Ratio”, which, for each question, produces a value that represents how likely the correct answer is in contrast to an incorrect answer. Then, averaging the truth ratio of all question pairs given by a model gives us this model’s confidence in these questions. Specifically, following the TOFU paper, for each question pair \([q, a]\) on Real Authors and World Facts, we treat each question $q$ as a multiple choice question associated with choices \({a_1, ..., a_n}\). We then generate \(\tilde{a}\), a paraphrased version of the answer $a$, and five perturbations \(\mathcal{A}_{\text{pert}}\) of \(a\) using GPT-4, which preserve the general template of $a$ while falsifying the factuality. Next, we calculate \(R_{\text{truth}}\) and truth ratio by
\[R_{\text{truth}} = \frac{\frac{1}{|\mathcal{A}_{\text{pert}}|}\sum_{\hat{a}\in\mathcal{A}_{\text{pert}}}P(\hat{a}|q)^{1/|\hat{a}|}}{P(\tilde{a}|q)^{1/|\tilde{a}|}}, \quad \text{Truth ratio} = \text{max}(0, 1-R_{\text{truth}}).\]3. Results and Discussions
Following the above procedures, for each rank \(r\), we fine-tune Phi-1.5B on TOFU (i.e., new author knowledge) with a sweep over the hyperparameters, including learning rate (LR) and weight decay (WD). The ROUGE score on new author knowledge throughout training is reported in the first column of Figure 1. Additionally, we evaluate the models’ performance on old author knowledge and old world knowledge throughout training and report them in the second and third columns of Figure 1.
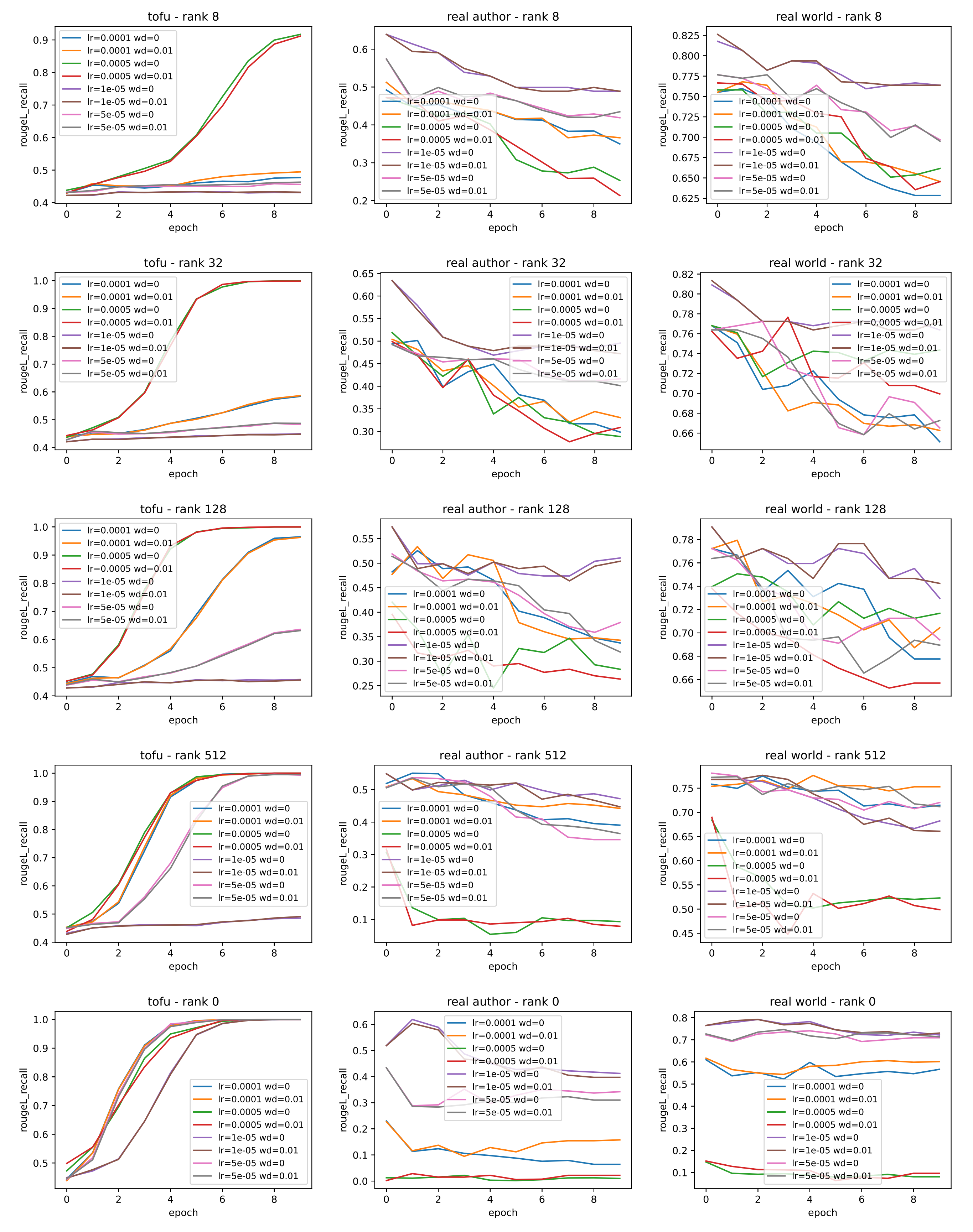
For \(r=\text{full}\) (the last row of Figure 2), all the hyperparameters yield fast convergence, so we choose the most commonly used pair (LR=1e-5, WD=0). We take the last model checkpoint before reaching ROUGE=0.9 on TOFU (full split) so as to avoid overfitting to the new knowledge. This picked “not-yet-overfit” model has an ROUGE score of 0.5 on Real Authors and 0.78 on World Facts.
When \(r=\{8, 32, 128, 512\}\), due to the smaller number of trainable parameters, only larger learning rates can converge reasonably fast. We choose the hyperparameters that reach ROUGE=0.9 the earliest on new data and recover the corresponding “not-yet-overfit” checkpoint. This yields (LR, WD) = (1e-4, 0) for \(r=8\), (5e-4, 0) for \(r=32\), (5e-4, 0) for \(r=128\) and (1e-4, 0.01) for \(r=512\).
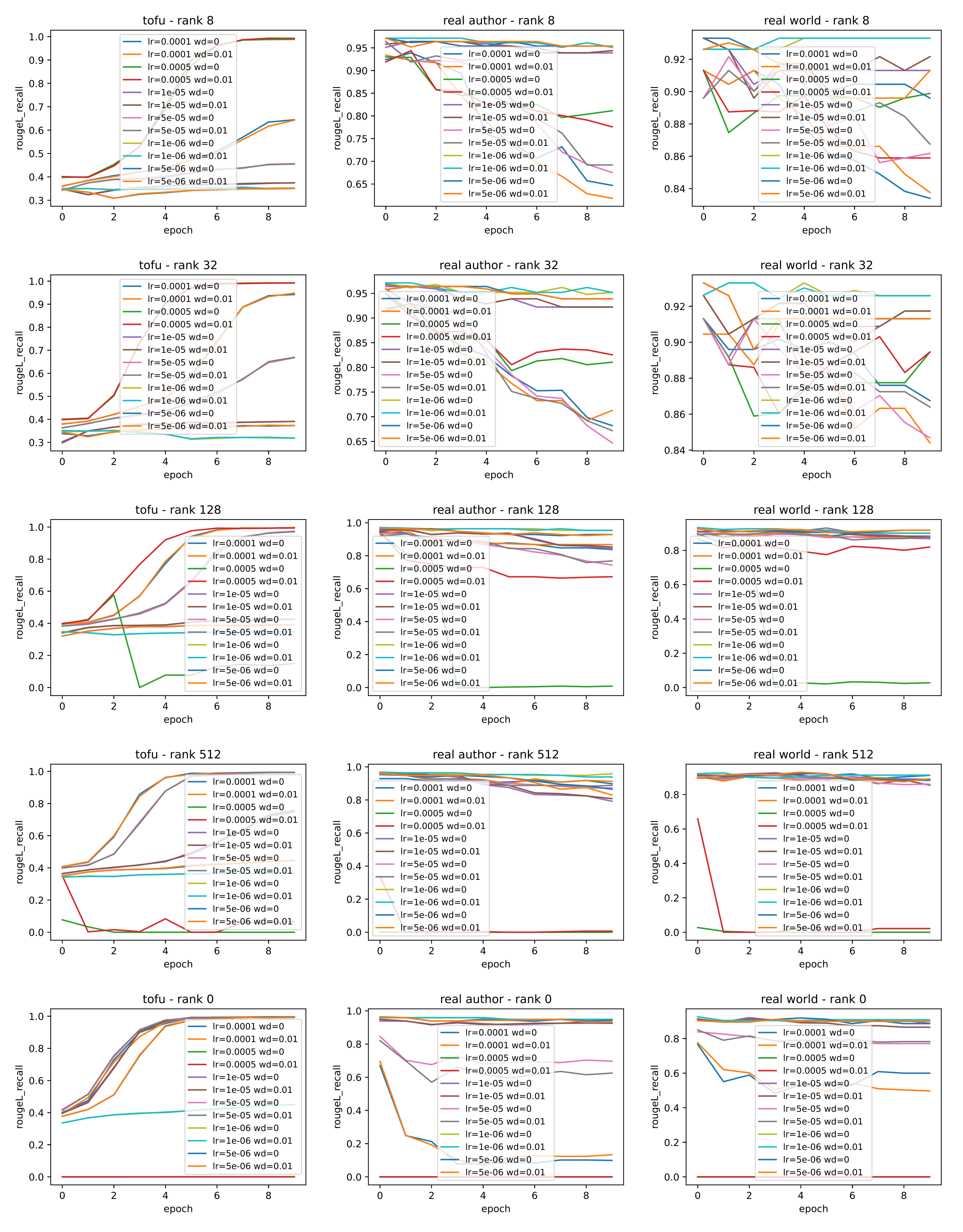
Similar to Phi-1.5B, for Llama-2-7B (Figure 2), we pick the hyperparameter set with the smallest learning rate such that the resultant model converges within 5 or 6 epochs. We obtain the optimal hyperparameter pairs (LR, WD) = (0.0005, 0) for \(r=8\), (0.0005, 0) for $r=32$, (0.0001,0) for \(r=128\), (5e-5, 0) for \(r=512\), and (1e-5, 0) for \(r=\text{full}\).
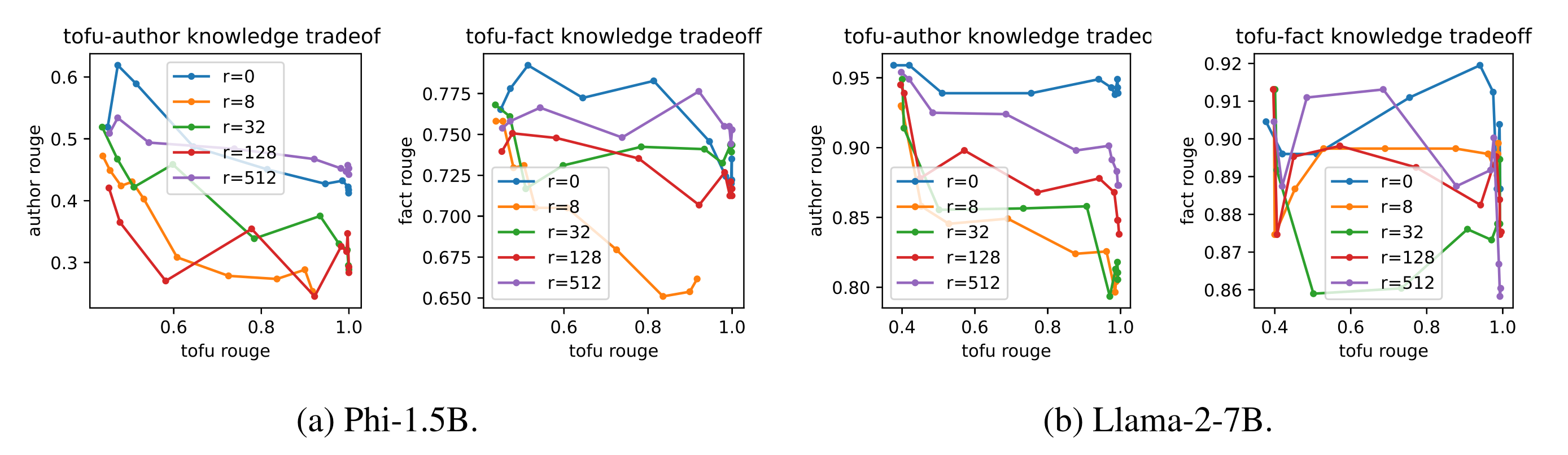
In Figure 3, we plot the ROUGE score for new knowledge on the x-axis and that for old knowledge on the y-axis for different ranks \(r=\{8,32,128,512,\text{full}\}\). We observe that
1. For both Phi-1.5B and Llama-2-7B, the ROUGE scores for old and knowledge are at odds with each other.
2. Large rank has better tradeoffs, especially when the new and old knowledge are of the same domain (i.e., author facts).
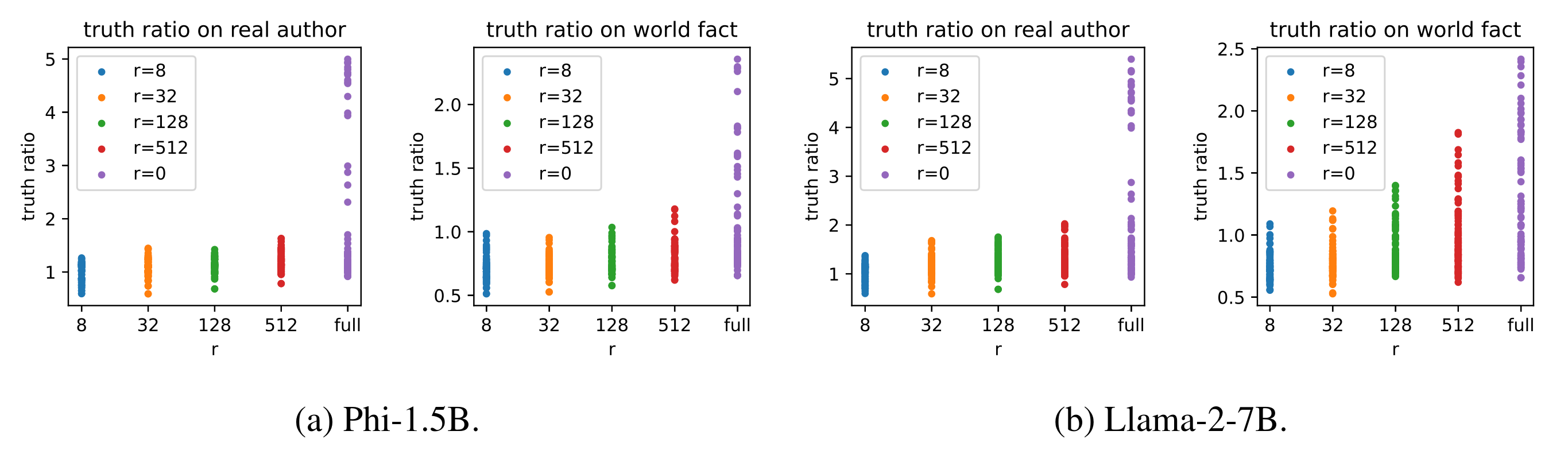
In Figure 4, we plot the truth ratio of models under different hyperparameters. We observe that after fine-tuning on new knowledge, larger ranks, especially full rank, perform better on old knowledge.
4. Future Work and Conclusion
First, we have observed the trend that “LoRA forgets more” holds especially well when the new and old knowledge are of the same domain (author facts in our case). It would be important to verify the occurrence of similar observations on knowledge other than author facts, such as world facts.
Second, it is also worthwhile to experiment with LoRA variants such as AdaLoRA
Overall, this work challenges the expressivity of LoRA. Though LoRA yields negligible losses in downstream task performance compared to full fine-tuning, it underperforms in preserving capabilities on old knowledge. Therefore, less lossy low-rank reparameterization are needed.